线上项目采用Spring Cloud作为整套的微服务体系,在微服务体系中,链路追踪是定位问题的绝佳手段。但是我们在引入Sleuth以及Zipkin的过程中发现Ribbon的重试机制发生了改变,导致Ribbon节点的重试到错误节点,引起最终请求失败。花费了几天的定位,发现是Sleuth以及Zipkin引入的Spring-Retry的组件引起的重试的bug,导致本应处于断路状态的节点的状态被错误清除。
默认情况下 Ribbon 的重试是利用Reactive Java 来做的,我们之前并没有主动的引入Retry包,重试功能虽然没有Rettry包强大,但是整体的重试机制是正常的。我大概阐述下问题的定位过程,相关的问题也很早提Issue到Spring 的Github了,时间一直不宽裕,写篇博文算是一个记录。
验证过程可以看Issue上的复现过程,这里主要从源码角度再总结分析一下为什么产生了断路状态的错误清除。Ribbon的基本的关键组件如下:
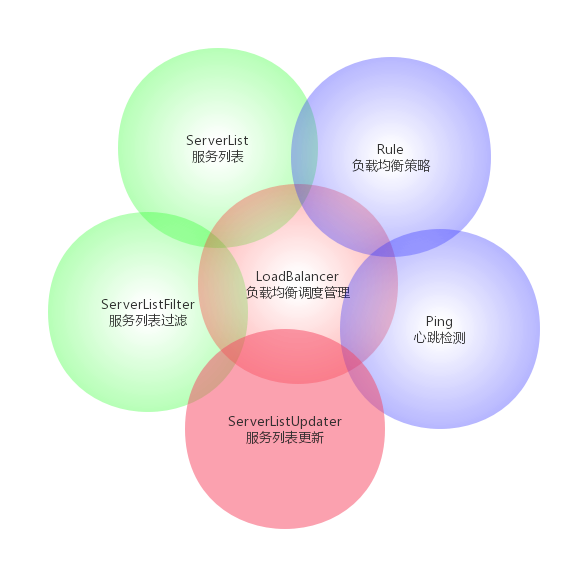
其中Ribbon默认的负载均衡类是com.netflix.loadbalancer.ZoneAwareLoadBalancer(当只有一个zone时,委托给DynamicServerListLoadBalancer选择,也是我们目前实际的场景) 负载均衡规则类是com.netflix.loadbalancer.AvailabilityFilteringRule 。
针对于服务列表的负载均衡选择机制,AvailabilityFilteringRule表现如下:
继承PredicateBasedRule类
- 基于服务有效性原则,使用AvailabilityPredicate类来过滤服务列表
- 过滤掉多次访问失败而处于断路状态的服务实例
- 过滤掉并发的连接数量超过阈值的服务实例
- 过滤完成按照RoundRobinRule策略访问
注意AvailabilityFilteringRule有一个职责是 过滤掉多次访问失败而处于断路状态的服务实例 ,本来AvailabilityFilteringRule 会将处于断路状态的实例做剔除,但是就像Issue的描述由于断路状态被错误清除,导致该Rule没有做过滤剔除,请求仍旧会打到本应断路的节点。
Ribbon是通过叫做ServerStats的类对象来维护每个实例的状态,其中有AtomicInteger successiveConnectionFailureCount的字段变量,当发生错误时会将该字段++,然后会根据 successiveConnectionFailureCount 计算 断路超时时间。但是如果某一次请求成功之后就会调用 clearSuccessiveConnectionFailureCount() 重置count为0。代码如下:
1 | public boolean isCircuitBreakerTripped(long currentTime) { |
问题产生于 LoadBalancerCommand ,这个封装了整个执行过程的类。
1 | // Use the load balancer |
LoadBalanceCommand 会将执行过程交给 RetryableFeignLoadBalancer , RetryableFeignLoadBalancer 再调用RetryTemplate 去做真正的执行。
1 |
|
初次选出的Server以及ServerStat会留在LoadBalanceCommand 方法中,即使第一个server请求出错,但是后面重试之后请求正常完成的话,最后也会被调用 onCompleted() 方法,将状态重置刷新。
该bug我测了Camden.SR7以及Edgware.SR4版本,均存在。其中Camden.SR7的问题更严重,它的ServerStat的刷新在retry过程中是不会被刷新的。
因为涉及到的组件Jar包过多以及Reactive编程,该Bug对我来讲相当有难度,有后续进展我会更新到博客上。目前考虑可以通过配置缩短Ribbon的节点信息刷新时间避免因为服务升级导致的错误请求量过多。主要是通过配置ribbon.ServerListRefreshInterval 参数以及eureka.client.registryFetchIntervalSeconds参数即可。另外请注意Eureka心跳刷新的时间参数不要自定义配置,会影响Eureka的自我保护模式的计算,导致一些意外情况。
参考文献